
Context Switching 문맥 교환
CPU에서 프로그램 실행을 잠시 중단하고 다른 프로그램을 실행하는 것
현재 실행중이던 프로세스가 (어떤 이유에서건) 중단되었때 행하는 기법이다. 만약 OS가 현재 실행중인 프로세스를 멈추고 다른 프로세스를 실행해야 할 때 실행한다.
먼저, 해당 프로세스의 레지스터값들을 저장한다. 나중에 해당 프로세스가 다시 CPU에 올라왔을 때, 이 레지스터값들을 복원하여(에를 들어 해당 값을 실제 물리 레지스터에 다시 저장함으로써) 일시정지 하였던 부분부터 재실행한다.
이 문맥 교환 시 만약 interrupt 등이 발생하면 곤란하므로 os는 인터럽트를 비활성화(불능화) 하거나, lock을 사용해 동시성 문제를 예방한다.
Scheduling이란?
운영 체제가 실행해야 하는 여러 프로그램이 있을 때, 어떤 프로그램을 실행시켜야 하는지 결정을 내리는 정책이다. 이 정책은 다양한 알고리즘으로 구현되는데, 대표적으로 선입 선출(FIFO), 최단 작업 우선(Shortest Job First), 최단 잔여시간 우선(Shortest Time-to-Completion First, STCF), 라운드 로빈(Round-Robin, RR), Multilevel Queue Scheduling이 있다.
스케줄링 평가 항목(scheduling metric)
스케줄링의 경우 다양한 평가 기준이 존재한다.
초기에는 단순한 반환 시간이라는 기준만 사용하지만, 시분할 기법을 사용하면서 응답 시간이라는 평가 기준이 생겼다. 왜냐하면 사용자들에게 어떤 프로그램이 '동시에'사용중이라는 환상을 주고자 일정 시간 간격을 두고 interrupt를 걸거나 시스템 콜을 통해 cpu의 주도권을 넘겨주어야 하는데 그 과정 중 어떤 프로세스의 응답 시간이 늦어지면 그런 환상을 줄 수 없기 때문이다.
- 반환 시간(turnaround time): 작업이 끝난 시점 - 작업이 도착한 시점
- 공정성(fairness) : RR이 대표(작은 시간 단위로 모든 프로세스에게 CPU를 분배하는 정책)
- 응답 시간(response time): 작업 도착할 때부터 처음 스케줄 될 때까지의 시간
CPU Scheduling 알고리즘
선입 선출 FCFS (First Come First Served) | 비선점
가장 이해하기 쉬우나, 만약 가장 먼저 도착하는 A가 차지하는 시간(반환 시간)이 경우 문제가 생긴다.
반환 시간이 짧은 작업들이 자원을 오래 사용하는 프로세스의 종료를 기다리는 현상을 convoy effect라고 표현한다.


최단 작업 우선 SJF (Shortest Job First) | 비선점
가장 짧은 실행 시간을 가진 작업부터먼저 실행시키는 알고리즘이다.


그러나 FIFO 와 마찬가지로 더 짧은 B,C가 늦게 도착하면 똑같은 Covey Effect가 발생한다. 짧은 거부터 실행하는데 이런 현상이 발생하는 이유는, 이 알고리즘이 이미 CPU를 선점하고 있는 프로세스를 쫓아내지 못하기 때문에(=선점하지 못함) 발생한다.
선점형 최단 작업 우선 (PSJF) / 최단 잔여시간 우선 SRTF (Shortest Remaining Time First) | 선점형
SJF 에 선점 기능을 추가한 알고리즘이다.
새로운 프로세스가 대기열에 들어오면 프로세스에 남아 있는 작업과 새로운 작업의 잔여 실행 시간을 계산하고 그 중 가장 작은 것부터 실행한다.

시분할 기법으로 등장한 한계
FIFO, SJF, PSJF (선입선출, 최단작업우선, 선점형 최단작업우선)은 어떤 기준으로든지 먼저 실행된 작업이 완전히 끝날 때까지 기다려야 하므로 응답 시간이 늦어질 수밖에 없다.
Round Robin (타임 슬라이싱)
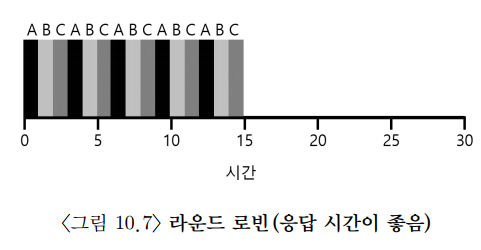
라운드 로빈 기법은 전체 작업이 완전히 끝날 때까지 기다리지 않는다. 일정 시간(타임 슬라이스 / 스케쥴링 퀀텀) 동안 실행한 후 실행 큐에 도착한 다른 작업을 실행한다. 주기는 인터럽트의 배수여야 한다.
타임 슬라이스가 짧으면 응답 시간 기준으로는 RR의 성능이 좋아진다. 그러나 너무 짧으면 context switch 비용이 증가해 성능에 영향을 끼친다. 반대로 반환 시간 기준으로는 RR은 최악의 정책이 된다.
Multilevel Queue Scheduling
cpu를 사용할 다음 순서를 기다리는 준비 큐(ready queue)를 여러 개의 큐로 분리해서, 큐 사이에도 우선순위를 부여하는 알고리즘이다. 각 queue는 서로 다른 알고리즘을 가질 수 있다.
동기화
os는 다수의 실행 유닛인 thread를 여럿 사용함으로써, 즉 병행성(concurrency)을 획득함으로써 CPU라는 자원을 효과적으로 사용할 수 있게 되었다. 다만, 다중 thread는 공유 자원이 존재하고, thread의 수행 순서가 스케쥴러에 의해 매번 다르게 정해져 결과를 에측할 수 없게 된다.
이것을 이해하기 위해선 아래 개념을 알아야 했다.
임계 영역(critical section)
같은 코드를 실행할 때 경쟁 조건이 발생하는 코드 부분
경쟁 조건(race condition)
여러 thread가 거의 동시에 임계 영역을 실행하려 할 때 발생하고, 비결정적인 결과를 낳는다. 명령어의 실행 순서에 따라 결과가 달라지는 상황이기도 함.
비결정적(indeterminate)
프로그램은 하나 이상의 경쟁 조건을 포함하기 때문에, 그 실행 결과는 각 thread가 실행된 시점에 의존한다. 그 결과 프로그램의 결과가 실행할 때마다 다르며, 기대하는 값과 다를 수 있다. 즉, 언제나 100% 동일한 결과로 결정되어지지 않는다.
상호 배제(mutual exclusion) | Mutex
하나의 thread가 임계 영역 내의 코드를 실행 중일 때는 다른 쓰레드가 실행할 수 도록 보장하는 속성. 하나의 스레드만 임계 영역에 진입할 수 있도록 보장하여 경쟁을 회피한다. 그 결과, 원하는 값을 결정론적으로 얻을 수 있도록 한다.
pintOS에서의 동기화
pintOS에서는 하나의 프로세스 자원을 여러 스레드가 공유하기에 생기는 필연적인 문제가 있다. 공유 자원에 동시에 접근할 때 실행 순서에 따라 결과값이 달라지는 현상인 Race condition 이다. 이것을 해결하기 위해서는 상호 배제한 접근을 보장하여 동기화 하여야 한다.
그렇다면 어떻게 상호 배제적인 접근을 보장할 수 있을까. pintOS에서는 미리 주어진 동기화 기본요소(조건?)들을 준다.
lock, semaphore, monitor와 condition variable이 그것이다.
Disabling Interrupts in PintOS
CPU의 인터럽트를 일시적으로 차단하는 방법으로, cpu의 인터럽트를 차단하면 다른 스레드가 현재 실행중인 스레드를 밀어내고 선점할 수 없게 된다. 반대로 말하자면, 인터럽트가 켜져 있다면 다른 스레드에 의해 선점될 수 있다. PintOS는 '(다른 스레드에 의해) 선점당할 수 있는(= 쫓겨날 수 있는?)' 커널 스레드이다.(Incidentally, this means that Pintos is a "preemptible kernel," that is, kernel threads can be preempted at any time) 전통적인 유닉스 시스템의 스레드는 "nonpreemptible"한 커널 스레드인데, 커널 스레드가 스케쥴러를 명시적으로 호출하여 소유권을 넘겨주는 지점에서만 커널 스레드를 선점할 수 있다. 즉, 현재 pintOS의 스레드는 언제 어디서 intrrupt가 걸리면 스케쥴이 됐든, 안 됐든 현재 소유하는 CPU 사용권을 뺏기므로, 동기화를 '명시적'으로 해주어야 한다. (그러지 않으면 thread가 cpu를 계획한 대로 사용하지 못하게 된다. 유저 프로그램은 두 타입의 커널 스레드 선점 속성 모 선점할 수 있다고 한다.) 이 인터럽트 비활성 옵션은 커널 스레드를 외부의 인터럽트 핸들러와 동기화할 때 사용하고, 그 외에는 기존의 동기화 primitives를 사용해야 한다.
/* Interrupts on or off? */
enum intr_level {
INTR_OFF, /* Interrupts disabled. */
INTR_ON /* Interrupts enabled. */
};
enum intr_level intr_get_level (void);
enum intr_level intr_set_level (enum intr_level);
enum intr_level intr_enable (void);
enum intr_level intr_disable (void);
Semaphores in PintOS
A semaphore is a nonnegative interger together
with two operators that manipulate it atomically
semaphore의 코드들
// synch.h
/* A counting semaphore. */
struct semaphore {
unsigned value; /* Current value. */
};
void sema_init (struct semaphore *, unsigned value);
void sema_down (struct semaphore *);
void sema_up (struct semaphore *);
// synch.c
/* Initializes semaphore SEMA to VALUE. A semaphore is a
nonnegative integer along with two atomic operators for
manipulating it:
- down or "P": wait for the value to become positive, then
decrement it.
- up or "V": increment the value (and wake up one waiting
thread, if any). */
void
sema_init (struct semaphore *sema, unsigned value) {
ASSERT (sema != NULL);
sema->value = value;
list_init (&sema->waiters);
}
/* Down or "P" operation on a semaphore. Waits for SEMA's value
to become positive and then atomically decrements it.
This function may sleep, so it must not be called within an
interrupt handler. This function may be called with
interrupts disabled, but if it sleeps then the next scheduled
thread will probably turn interrupts back on. This is
sema_down function. */
void
sema_down (struct semaphore *sema) {
enum intr_level old_level;
ASSERT (sema != NULL);
ASSERT (!intr_context ());
old_level = intr_disable ();
while (sema->value == 0) {
list_push_back (&sema->waiters, &thread_current ()->elem);
thread_block ();
}
sema->value--;
intr_set_level (old_level);
}
/* Up or "V" operation on a semaphore. Increments SEMA's value
and wakes up one thread of those waiting for SEMA, if any.
This function may be called from an interrupt handler. */
void
sema_up (struct semaphore *sema) {
enum intr_level old_level;
ASSERT (sema != NULL);
old_level = intr_disable ();
if (!list_empty (&sema->waiters))
thread_unblock (list_entry (list_pop_front (&sema->waiters),
struct thread, elem));
sema->value++;
intr_set_level (old_level);
}세마포어는 하나의 음이 아닌 정수(0, 그리고 양수)( nonnegative integer)와 두 개의 operater로 이루어진다. 음이 아닌 정수는 '사용 가능한 공유 자원의 갯수' 를 뜻하고, 이 수는 세마포어 내의 operator로만 조작 가능하다.
Down / P 는 값이 양수가 될 때까지 기다렸다가, 값이 양수가 된다면 값을 줄인다.
Up / V 는 값을 증가시킨다.(그리고, 기다리고 있는 thread가 있다면 깨운다.)
코드상 sema down/ sema up은 모두 내부에서 interrupt 비활성화와 thread block, unblock이 이루어진다.
단일 이벤트 대기에 세마포어 사용하기 (semaphore.value == 0)
thread A가 먼저 실행되지만 B의 종료를 기다린 뒤, A가 마저 작업을 시작하는 경우.
세마포어는 0으로 초기화 된 채 어떤 특정 이벤트가 정확히 한 번 발생하기를 기다려 사용될 수 있다. 만약 어떤 thread A와 thread B가 있고, A가 B를 시작시키고(A내부에서 B호출 등), B의 활동이 완료되었음을 알리는 시그널을 기다린 뒤에야 움직이도록 작동시키려면 이렇게 해야 한다.
- A가 0으로 초기화한 세마포어를 생성하고
- B에게 넘겨준다.
- A는 B에게 넘겨준 뒤 semaphore를 "down" 한다. (sema_down을 호출한다.
threadA stops execution at sema_down () until threadB called sema_up () 해석
void
sema_down (struct semaphore *sema) {
enum intr_level old_level; //원자성을 보장하기 위하여
ASSERT (sema != NULL);
ASSERT (!intr_context ());
old_level = intr_disable ();
//세마포어 값 확인: while 루프를 사용하여 세마포어의 값이 0인지 확인
while (sema->value == 0) {
//대기 리스트에 추가
list_insert_ordered(&sema->waiters, &thread_current()->elem, priority_more, NULL);
//스레드 블록(현재 스레드를 블록 상태로 전환)
thread_block ();
}
sema->value--;
intr_set_level (old_level);
}-
- 여기서 sema_down코드를 본다면 바로 이 지점(위 코드)이다.
- 이 경우, 현재 sema의 value가 0이므로, while문에 걸려 stop한다.
- 현재 값이 0이므로 while문 안으로 들어간다.(해당 세마포어에 대해 대기한다. while문을 활용한 대기 구현)
- 현재 스레드는 세마포어에 대한 대기 리스트(wait list)에 자신을 추가하고, 대기 상태로 전환한다.
- thread를 block한다. (cpu에 올라가지 않을 것이다. 다른 스레드가 실행 가능해졌다.)
- threadA stops execution at sema_down () until threadB called sema_up ()
/* Up or "V" operation on a semaphore. Increments SEMA's value
and wakes up one thread of those waiting for SEMA, if any.
This function may be called from an interrupt handler. */
void
sema_up (struct semaphore *sema) {
enum intr_level old_level;
ASSERT (sema != NULL);
old_level = intr_disable ();
if (!list_empty (&sema->waiters))
thread_unblock (list_entry (list_pop_front (&sema->waiters),
struct thread, elem));
sema->value++;
intr_set_level (old_level);
}- 이후 B가 실행되고, 어떤 이벤트가 실행 종료된 뒤 semaphore를 Up 한다.( sema_up을 호출한다.)
- 코드를 보면 위쪽 상황이다. 먼저 인터럽트를 비활성화하고...
- B가 sema_up을 호출하면 대기 리스트를 확인하고 unblock한다. (자고 있던 A가 일어난다)
- 그 뒤 세마포어 값을 증가시킨다.
- 인터럽트를 재활성화한다
- A는 깨어나고, 드디어 while 루프에서 벗어나, sema vlaue를 감소시킨다. 이 뜻은, 세마포어의 자원을 현재 하나 사용하고 있다는 뜻이다.(그리고, 본래 초기화한 0이 된다.)
- 즉, A가 실행된다.
이렇게 함으로써, A와 B의 실행 순서가 보장된다!
/* Atomically releases LOCK and waits for COND to be signaled by
some other piece of code. After COND is signaled, LOCK is
reacquired before returning. LOCK must be held before calling
this function.
The monitor implemented by this function is "Mesa" style, not
"Hoare" style, that is, sending and receiving a signal are not
an atomic operation. Thus, typically the caller must recheck
the condition after the wait completes and, if necessary, wait
again.
A given condition variable is associated with only a single
lock, but one lock may be associated with any number of
condition variables. That is, there is a one-to-many mapping
from locks to condition variables.
This function may sleep, so it must not be called within an
interrupt handler. This function may be called with
interrupts disabled, but interrupts will be turned back on if
we need to sleep. */
void
cond_wait (struct condition *cond, struct lock *lock) {
struct semaphore_elem waiter;
ASSERT (cond != NULL);
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (lock_held_by_current_thread (lock));
sema_init (&waiter.semaphore, 0);
list_insert_ordered(&cond->waiters, &waiter.elem, sema_priority_more, NULL);
lock_release (lock);
sema_down (&waiter.semaphore);
lock_acquire (lock);
}자원 접근을 제어하기 (semaphore.value == 1)
thread A가 먼저 실행되고, A의 작업이 완료된 뒤 B의 실행을 보장한다
- semaphore를 1로 초기화한다.
- 그 자원을 사용하려는 코드가 down 하여 값을 0으로 만든다.
- 사용이 끝나면 1으로 만들어 잠금을 해제한다.
lock과 사용 방식이 유사하다. 실제 lock은 이렇게, semaphore를 init할 때 그 값을 1로 지정하여 사용한다.
/* Initializes LOCK. A lock can be held by at most a single
thread at any given time. Our locks are not "recursive", that
is, it is an error for the thread currently holding a lock to
try to acquire that lock.
A lock is a specialization of a semaphore with an initial
value of 1. The difference between a lock and such a
semaphore is twofold. First, a semaphore can have a value
greater than 1, but a lock can only be owned by a single
thread at a time. Second, a semaphore does not have an owner,
meaning that one thread can "down" the semaphore and then
another one "up" it, but with a lock the same thread must both
acquire and release it. When these restrictions prove
onerous, it's a good sign that a semaphore should be used,
instead of a lock. */
void
lock_init (struct lock *lock) {
ASSERT (lock != NULL);
lock->holder = NULL;
sema_init (&lock->semaphore, 1);
}
Lock
자원의 접근을 제어하는 용도로 사용되는(s.value===1) 세마포어와 유사하다. release, acquire를 사용한다.
lock의 코드들
/* Initializes LOCK. A lock can be held by at most a single
thread at any given time. Our locks are not "recursive", that
is, it is an error for the thread currently holding a lock to
try to acquire that lock.
A lock is a specialization of a semaphore with an initial
value of 1. The difference between a lock and such a
semaphore is twofold. First, a semaphore can have a value
greater than 1, but a lock can only be owned by a single
thread at a time. Second, a semaphore does not have an owner,
meaning that one thread can "down" the semaphore and then
another one "up" it, but with a lock the same thread must both
acquire and release it. When these restrictions prove
onerous, it's a good sign that a semaphore should be used,
instead of a lock. */
void
lock_init (struct lock *lock) {
ASSERT (lock != NULL);
lock->holder = NULL;
sema_init (&lock->semaphore, 1);
}
/* Acquires LOCK, sleeping until it becomes available if
necessary. The lock must not already be held by the current
thread.
This function may sleep, so it must not be called within an
interrupt handler. This function may be called with
interrupts disabled, but interrupts will be turned back on if
we need to sleep. */
void
lock_acquire (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (!lock_held_by_current_thread (lock));
sema_down (&lock->semaphore);
lock->holder = thread_current ();
}
/* Releases LOCK, which must be owned by the current thread.
This is lock_release function.
An interrupt handler cannot acquire a lock, so it does not
make sense to try to release a lock within an interrupt
handler. */
void
lock_release (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (lock_held_by_current_thread (lock));
lock->holder = NULL;
sema_up (&lock->semaphore);
}
- pintOS에서 lock은 초기값이 1인 세마포어의 특수한 형태이다.
- semaphore와 달리 lock은 소유가 가능하다. 따라서 semaphore처럼 여러 스레드가 up/down을 수행할 수 없고, 오직 acquire를 호출한 owner 스레드만 release 를 할 수 있다.
- 한번에 하나의 thread만 소유할 수 있다.
lock_init의 특징: lock 의 소유주가 없음을 NULL 로 명시한다.
lock_acquire의 특징: 현재 이 함수를 호출한 스레드가 lock을 소유하고 있지 않아야 한다.
lock_release: 반드시 현재 스레드가 락을 갖고 있어야 한다.
Monitor in PintOS
멀티스레딩 환경에서 공유하는 데이터에 안전하게 접근할 수 있도록 고안되었다. 세마포어와 락은 각각 단순하게 데이터 접근 횟수나 데이터 접근 자체를 제어하는데, 이를 감싸 캡슐화한 동기화 메커니즘이다.
monitor lock
모니터 lock으로 보호되는 데이터에 접근하려면, "모니터에 있어야in the monitor"한다.
이 권한이 있다면 스레드는 데이터를 읽거나 수정할 수 있다.
condition variables
모니터 내에서의 코드가 특정 조건이 참이 되기를 기다리는 스레드를 관리하고, 계속 진행하기 위해 사용된다. (예: 데이터 도착 또는 이벤트 이후 시간 경과) 특정 조건을 기다려야 하는 동안 이 조건 변수를 기다리고, 참이 되면 모니터 lock이 해제되고 waiter 리스트에서 하나를 깨우거나, 모든 대기자를 깨운다.
여러 방면으로 활용할 수 있을 것 같은 개념이라, 더 깊게 볼만한 주제 같다.
조금 어려웠는데 함께 공부하니 이해가 될 거 같다. 아래는 다른 팀과 함께 공부한 판서 찰칵!
codes in PintOS
/* Atomically releases LOCK and waits for COND to be signaled by
some other piece of code. After COND is signaled, LOCK is
reacquired before returning. LOCK must be held before calling
this function.
The monitor implemented by this function is "Mesa" style, not
"Hoare" style, that is, sending and receiving a signal are not
an atomic operation. Thus, typically the caller must recheck
the condition after the wait completes and, if necessary, wait
again.
A given condition variable is associated with only a single
lock, but one lock may be associated with any number of
condition variables. That is, there is a one-to-many mapping
from locks to condition variables.
This function may sleep, so it must not be called within an
interrupt handler. This function may be called with
interrupts disabled, but interrupts will be turned back on if
we need to sleep. */
void
cond_wait (struct condition *cond, struct lock *lock) {
struct semaphore_elem waiter;
ASSERT (cond != NULL);
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (lock_held_by_current_thread (lock));
sema_init (&waiter.semaphore, 0);
list_insert_ordered(&cond->waiters, &waiter.elem, sema_priority_more, NULL);
lock_release (lock);
sema_down (&waiter.semaphore);
lock_acquire (lock);
}
/* If any threads are waiting on COND (protected by LOCK), then
this function signals one of them to wake up from its wait.
LOCK must be held before calling this function.
An interrupt handler cannot acquire a lock, so it does not
make sense to try to signal a condition variable within an
interrupt handler. */
void
cond_signal (struct condition *cond, struct lock *lock UNUSED) {
ASSERT (cond != NULL);
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (lock_held_by_current_thread (lock));
if (!list_empty (&cond->waiters)) {
list_sort(&cond->waiters, sema_priority_more, NULL);
sema_up (&list_entry (list_pop_front (&cond->waiters), struct semaphore_elem, elem)->semaphore);
}
}
gitbook의 예시로 이해해보면 될 것 같다. 쉽게 말해서 lock과 semaphore 기능을 합친
pintOS에서의 문맥 교환
여기(링크)에서 미리 정리한 바와 같이, 실질적인 문맥 교환(레지스터 정보 저장 및 복원)은 thread_launch에서 발생한다.
Priority Scheduling in PintOS
Implement priority scheduling and priority donation in Pintos.
현재 pintOS 코드는 단순히 FIFO로 스케쥴링된다. 비선점이며, 먼저 온 task가 처리되고, 그것이 다 끝날 때까지 기다린다. 이것을 thread 내부의 priority에 따라 높은 우선순위를 가진 스레드가 ready list에 추가될 때 cpu에서 실행중인 thread에게서 cpu 사용권을 빼앗아와야 한다.
lock, semaphore, conditiona variable 등으로 당장 기다려야 할 때에는, thread의 우선순위를 언제든지 변경할 수 있게 구현해야한다. 변경 직후 우선순위에 따라 CPU를 양보해야 하는 건 필수다.
thread_yield, thread_unblock
list에 삽입될 때 priority에 맞춰 삽입될 수 있도록 코드를 수정한다.
/* Yields the CPU. The current thread is not put to sleep and
may be scheduled again immediately at the scheduler's whim. */
void
thread_yield (void) {
struct thread *curr = thread_current ();
enum intr_level old_level;
ASSERT (!intr_context ());
old_level = intr_disable ();
if (curr != idle_thread)
list_insert_ordered(&ready_list, &curr->elem, priority_more, NULL);
do_schedule (THREAD_READY);
intr_set_level (old_level);
}
bool
priority_more (const struct list_elem *a_, const struct list_elem *b_,
void *aux UNUSED) {
const struct thread *a = list_entry (a_, struct thread, elem);
const struct thread *b = list_entry (b_, struct thread, elem);
return a->priority > b->priority;
}
/* Transitions a blocked thread T to the ready-to-run state.
This is an error if T is not blocked. (Use thread_yield() to
make the running thread ready.)
This function does not preempt the running thread. This can
be important: if the caller had disabled interrupts itself,
it may expect that it can atomically unblock a thread and
update other data. */
void
thread_unblock (struct thread *t) {
enum intr_level old_level;
ASSERT (is_thread (t));
old_level = intr_disable ();
ASSERT (t->status == THREAD_BLOCKED);
list_insert_ordered(&ready_list, &t->elem, priority_more, NULL);
t->status = THREAD_READY;
intr_set_level (old_level);
}
Preempt (선점) 구현
우선순위에 따라 스케쥴링 되기 때문에, thread 생성시최대 우선순위를 지녔는지 확인하는 함수를 생성 후 thread_create에 삽입해준다. 또한 priority를 set할 때 max를 테스트(확인) 하는 함수도 추가해준다.
/* 현재 실행중인 스레드의 우선순위보다 더 높은 것이 있다면 양보하는 함수 */
void
test_max_priority(void) {
if (!list_empty(&ready_list)) {
struct thread *top_pri = list_begin(&ready_list);
if (!intr_context() && priority_more(top_pri, &thread_current()->elem, NULL))
{
thread_yield();
}
}
}
////////////
tid_t thread_create(const char *name, int priority,
thread_func *function, void *aux)
{
...
/* Add to run queue. */
thread_unblock(t);
test_max_priority(();
return tid;
}
///////////////
/* Sets the current thread's priority to NEW_PRIORITY. */
void
thread_set_priority (int new_priority) {
if (thread_mlfqs) {
return;
}
thread_current()->original_priority = new_priority;
// thread_current()->priority = new_priority;
test_max_priority();
}
cond_wait과 cond_signal에서 semaphore 내에 있는 대기자들 waiters의 목록을 확인하고 순서를 바꾸어 준다.
// synch.c
bool
sema_priority_more (const struct list_elem *a_, const struct list_elem *b_, void *aux UNUSED) {
const struct semaphore_elem *a = list_entry (a_, struct semaphore_elem, elem);
const struct semaphore_elem *b = list_entry (b_, struct semaphore_elem, elem);
const struct list *waiter_a = &(a->semaphore.waiters);
const struct list *waiter_b = &(b->semaphore.waiters);
return priority_more(list_begin(waiter_a), list_begin(waiter_b), NULL);
}
void
cond_wait (struct condition *cond, struct lock *lock) {
struct semaphore_elem waiter;
ASSERT (cond != NULL);
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (lock_held_by_current_thread (lock));
sema_init (&waiter.semaphore, 0);
list_insert_ordered(&cond->waiters, &waiter.elem, sema_priority_more, NULL);
lock_release (lock);
sema_down (&waiter.semaphore);
lock_acquire (lock);
}
void
cond_signal (struct condition *cond, struct lock *lock UNUSED) {
ASSERT (cond != NULL);
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (lock_held_by_current_thread (lock));
if (!list_empty (&cond->waiters)) {
list_sort(&cond->waiters, sema_priority_more, NULL);
sema_up (&list_entry (list_pop_front (&cond->waiters), struct semaphore_elem, elem)->semaphore);
}
}
//// thread.c
bool
priority_more (const struct list_elem *a_, const struct list_elem *b_,
void *aux UNUSED) {
const struct thread *a = list_entry (a_, struct thread, elem);
const struct thread *b = list_entry (b_, struct thread, elem);
return a->priority > b->priority;
}
'공부기록 > OS' 카테고리의 다른 글
| [TIL / WIL] [Project 1] MLFQS + Advanced Scheduler in PintOS (0) | 2023.12.04 |
|---|---|
| [TIL][Project 1] Priority Donation (0) | 2023.12.04 |
| [TIL][Project 1] process & thread in PintOS + Alarm Clock (0) | 2023.11.25 |
| [TIL][Project 1] 이해하기: interrupt frame, idle, 그리고 busy waiting (0) | 2023.11.24 |
| [TIL][Thur] PintOS Threads Keywords (0) | 2023.11.23 |