
Implement system call infrastructure.
Interrupts : OS의 매커니즘
OS가 cpu를 사용하고 있는 user program으로부터 제어권을 다시 가져올 수 있는 방법들이 여럿 있다.
- H/W interrupt (External Interrupt): 하드웨어의 timer, 외부 장치의 I/O에서 발생. <CPU의 외부>
- S/W interrupt (Internal Interrupt): 프로그램(sw)에서 발생. <CPU의 내부>
- Exception
- Trap
- System Call: x86-64에서 syscall이라는 명령어 도입, system call handler를 빠르게 호출.
- system call을 호출하기 위해 필요한 건 system call number와 추가 인자들이며, 이것은 syscall 명령어를 호출하기 전에, 이 두 개를 제외하고 레지스터에 설정되어 있어야 한다.
- %rax : syscall number
- 4th argument는 %r10에 설정되어 있어야 한다. (%rxc)
- system call을 호출하기 위해 필요한 건 system call number와 추가 인자들이며, 이것은 syscall 명령어를 호출하기 전에, 이 두 개를 제외하고 레지스터에 설정되어 있어야 한다.
user 가 커널 기능을 사용하기 위해, 내부적인 interrupt를 걸어 user mode에서 kernel mode 에서만 사용 가능한 특권 명령어를 사용할 수 있는 인터페이스를 호출한다. 이것이 시스템 콜이다.

System Call , in PintOS
https://casys-kaist.github.io/pintos-kaist/project2/system_call.html
모두 userprog/syscall.c에서 작성한다. 깃북 친절하게 어떻게 구현하면 되는지 적혀 있다.
[Process related] : halt, exit, exec, fork, wait ..
프로세스와 관련된 시스템 콜들.
halt
Terminates Pintos by calling power_off()
void halt(void) {
power_off();
}전원을 끄는 함수를 호출해 pintOS를 종료한다. 이 함수를 호출하면 deadlock같은 정보를 잃게 된다고 한다.
exit : Process Termination Message
Terminates the current user program, returning status to the kernel
void exit (int status) {
thread_current()->exit_status = status;
printf("%s: exit(%d)\n", thread_name(), thread_current()->exit_status);
thread_exit();
}
//thread.c
/* Deschedules the current thread and destroys it. Never
returns to the caller. */
void
thread_exit (void) {
ASSERT (!intr_context ());
#ifdef USERPROG
process_exit ();
#endif
/* Just set our status to dying and schedule another process.
We will be destroyed during the call to schedule_tail(). */
intr_disable ();
do_schedule (THREAD_DYING);
NOT_REACHED ();
}
//process.c
/* Exit the process. This function is called by thread_exit (). */
void
process_exit (void) {
struct thread *curr = thread_current ();
/* TODO: Your code goes here.
* TODO: Implement process termination message (see
* TODO: project2/process_termination.html).
* TODO: We recommend you to implement process resource cleanup here. */
for (int i = 2; i < FDCOUNT_LIMIT; i++) {
close(i);
}
palloc_free_multiple(curr->fd_table, FDT_PAGES);
file_close(curr->running);
process_cleanup ();
sema_up(&curr->wait_sema);
sema_down (&curr->exit_sema);
}현재 user program을 종료하는 함수. 커널의 status를 반환한다. (halt와 다른 점이 이것이다.)
만약 process의 부모가 이 종료를 wait하고 있다면 wait이 기다리는 게 바로 이 커널의 status이다. (Process Termination Message가 여기서 구현된다.)
실제 process의 exit는 process.c의 process_exit에서 실행된다.
먼저 FDT의 메모리를 반환한다(아마 이 테이블 내의 파일도 모두 닫을 것이다)
현재 실행중인 스레드가 실행하는 파일도 닫는다.
process를 cleanup한다.
exit할 때, semaphore로 동기화를 해주기 위해 thread 구조체를 아래처럼 수정해주어야 한다. 먼저, 현재 진행중인 스레드의 wait의 세마포어를 1로 증가시켜 대기 중일 부모 프로세스에게 대기를 진입할 수 있는 허가를 내려준다. 두번째로는 현재 러닝중인 스레드의 exit 세마포어를 감소시키는데, 만약 종료 되기 전 처리되어야 하는 작업들이 진행중일 때 exit_sema는 이 작업을 진행하지 않고 대기한다. 1이 되면 다시 작업을 진행해 exit가 정상적으로 처리된다.
Update thread struct .. . .
thread 구조체에 exit 와 wait의 세마포어를 만들어주고, init_thread에 초기화(sema_init, value는 0)를 추가해 준다. 또한 바로 뒤에서 쓰일 것이지만, thread가 부모가 되었을 때 어떤 스레드들이 child인지 정보를 알고 있어야 하므로 관련 리스트도 추가해준다.
struct thread {
/* Owned by thread.c. */
tid_t tid; /* Thread identifier. */
enum thread_status status; /* Thread state. */
char name[16]; /* Name (for debugging purposes). */
int priority; /* Priority. */
/* Shared between thread.c and synch.c. */
struct list_elem elem; /* List element. */
...
/* Priority donation */
...
/* Advanced Scheduler */
...
/* process */
struct list child_list;
struct list_elem child_elem;
struct semaphore wait_sema;
struct semaphore fork_sema;
struct semaphore exit_sema;
int exit_status;
struct intr_frame parent_tf;
#ifdef USERPROG
/* Owned by userprog/process.c. */
uint64_t *pml4; /* Page map level 4 */
#endif
#ifdef VM
...
#endif
/* Owned by thread.c. */
struct intr_frame tf; /* Information for switching */
unsigned magic; /* Detects stack overflow. */
/* filesys */
...
}wait
Waits for a child process pid and retrieves the child's exit status
- child process의 pid를 기다리고, 자식의 종료 상태를 탐색한다. 즉, 자식 process의 pid가 살아있다면 종료될 때가지 wait하고 종료되면 자식이 종료된 상태를 받아 반환한다.
- 만약 pid가 exit를 호출하지 않고 종료되었다면(kernel에게 종료되었다면) wait(pid)는 반드시 -1을 반환한다.
- 만약 부모 프로세스가 대기중일 때 자식 프로세스가 종료되었다면 커널은 반드시 그 부모 프로세스에게 자식의 종료 상태를 검색하고 커널에게 종료당했음을 통보(?) 해야 한다.
wiat은 다음 조건 중 하나가 참이면 반드시 -1을 반환하며 실패한다.
- pid가 호출하는 프로세스의 직계자식(직접적인 자식?) 프로세스를 참조하지 않을 때. 만약 현재 호출하는 thread A 가 아래 같은 가계도를 가진다고 생각하자.
- fork 호출 성공으로 획득한 pid만 직접적인 자식이 된다. 아래 그림에서 A가 fork를 호출해 B를 spawn하고, B가 spawn 하여 C를 얻었다면, A와 B는 직계이고 B와 C는 직계이지만 A와 C는 직계가 이니다. 또한 fork하여 생성된 자식 thread와 프로세스는 상속되지 않는다.

- fork 호출 성공으로 획득한 pid만 직접적인 자식이 된다. 아래 그림에서 A가 fork를 호출해 B를 spawn하고, B가 spawn 하여 C를 얻었다면, A와 B는 직계이고 B와 C는 직계이지만 A와 C는 직계가 이니다. 또한 fork하여 생성된 자식 thread와 프로세스는 상속되지 않는다.
- wait을 호출한 프로세스가 이미 pid에 대해 wait을 호출했을 때: 즉, 한번에 하나의 프로세스만 wait할 수 있단 뜻이다.
모든 wait이 발생하는 경우를 핸들링해야 한다. 그리고 중요한 건 pintOS가 초기 프로세스(inital process)가 종료될 때까지 pintOS가 종료되지 않도록 보장해야 한다.
int wait (tid_t tid) {
return process_wait (tid);
}
//process.c
/* Waits for thread TID to die and returns its exit status. If
* it was terminated by the kernel (i.e. killed due to an
* exception), returns -1. If TID is invalid or if it was not a
* child of the calling process, or if process_wait() has already
* been successfully called for the given TID, returns -1
* immediately, without waiting.
*
* This function will be implemented in problem 2-2. For now, it
* does nothing. */
int
process_wait (tid_t child_tid) {
/* XXX: Hint) The pintos exit if process_wait (initd), we recommend you
* XXX: to add infinite loop here before
* XXX: implementing the process_wait. */
struct thread *child;
if (!(child = get_child_thread(child_tid))) {
return -1;
}
sema_down (&child->wait_sema);
list_remove (&child->child_elem);
int exit_status = child->exit_status;
sema_up (&child->exit_sema);
return exit_status;
}앞에서 무한 루프를 생성했다면 지우면 된다.
1. wait 은 child process의 pid가 살아있다면 종료될 때까지 기다려야 한다. (첫번째 sema_down) 대기하는 방법이 sema_down, 즉 세마포어를 활용한 대기 모드인데, wait_sema가 0일 때에는 대기할 것이다. 위의 process_exit에서, sema up하여 종료 에정임을 알린다면, 이제 비로소 sema down에서의 대기가 풀리고 list_remove를 거쳐 child의 exit status를 받아온다.
2. 이 작업이 처리되고 나서, 비로소 정말 끝내라고 semaphore를 1로 up해주면서 진입 허가 신호를 보내 준다.
exec
Change current process to the executable
whose name is given in cmd_line,passing any given arguments.
cmd_line에서 주어진 실행파일의 이름으로 현재 프로세스를 교채한다.(즉, 실행하란 소리다.)
- 이 함수는 성공한 경우 return값이 없고, 실패할 때(로드할 수 없거나 다른 이유에서 실행할 수 없을 때) -1을 반환한다.
- exec라고 불리는 스레드의 이름을 변경하지 않는다.
앞에서 한 argument passing에서 거의 다 구현했다. check address는 적합한 user memory에 참조하는지 확인하는 코드이다.
int exec (const char *file) {
check_address(file);
if (process_exec((void *) file) < 0) {
exit(-1);
}
}
fork
Create new process which is the clone of current process
with the name THREAD_NAME
할일이 많다!
fork개념도 이해해야한다. fork는 쉽게 말해서 clone하는 system call이다. clone하기 때문에 분화된 프로세스는 이전까지의 데이터 등을 고스란히 사용 가능하고, 아래 그림처럼 그릴 수 있다.(그런데 이 형태가 식기 포크랑 비슷하다고 해서 이름이 fork가 되었다고 한다.) 우리는 이번에 이것을 구현하면서 복제할 때 어디까지 복제하는지 이번에 직접 눈으로 확인할 수 있다.(와~!)

- 특정 레지스터(%RBX, %RSP, %RBP, and %R12 - %R15) 들을 제외한 다른 레지스터 값은 복제하지 않아도 된다. 그러나 위의 레지스터들은 반드시 복제해야 하고, 특수한 역할을 담당하는 레지스터들도 모두 복사해야 한다.
- fork(복제)되어 생성된 자식 프로세스(thread)의 pid를 반환해야 유효한 pid가 된다.
- 자식 프로세스의 경우엔 반환 값이 0이 되며, 자식 프로세스는 파일 디스크립터와 가상 메모리 공간 등이 부모와 중복된 리소스를 가져야 한다.
- 부모 프로세스는 자식이 성공적으로 복제되었음을 확인받은 뒤에야 fork에서 복귀할 수 있다. 만약 실패한다면 TID_ERROR를 반환한다.
- mmu.c의 pml4_for_each()를 사용하여 테이블 구조를 포함한 모든 유저 메모리 공간을 복제한다. 그러기 위해서 우리가 일부를 매꿔야 한다.
먼저 thread name이 유효한 메모리 주소인지 확인한 뒤에 process_fork에서 실제 일을 처리한다.
process fork를 실행중인 current thread가 바로 부모 스레드가 되고, 현재 스레드의 레지스터 정보를 담고 있는 if를 인자로 받은 if에 복제한다. 그 다음에 thread를 생성하는데, thread chreate의 인자로 do_fork를 받는다. (이게 진짜다!) 반환하는 값이 ERROR TID를 반환하면 그것을 반환하고, fork seam(물론, thread구조체에 미리 만들어 두어야 한다)를 down해 잠시 대기하다가 어디선가 up하여 대기가 풀리면 마저 진행한다.
tid_t fork (const char *thread_name, int (*f)(int)) {
check_address(thread_name);
return process_fork(thread_name, f);
}
/* Clones the current process as `name`. Returns the new process's thread id, or
* TID_ERROR if the thread cannot be created. */
tid_t
process_fork (const char *name, struct intr_frame *if_ UNUSED) {
/* Clone current thread to new thread.*/
struct thread *parent = thread_current ();
memcpy(&parent->parent_tf, if_, sizeof (struct intr_frame));
tid_t tid = thread_create (name, PRI_DEFAULT, __do_fork, parent);
if (tid == TID_ERROR)
return tid;
struct thread *child = get_child_thread(tid);
sema_down(&child->fork_sema);
if (child->exit_status == TID_ERROR) {
return TID_ERROR;
}
return tid;
}
do_fork
여기서 do_fork의 current thread는 thread_create를 실행하고 있는 thread이므로, 자식 thread가 된다.
부모 thread의 실행 컨텍스트를 복사하는 thread function(thread_create()에 들어가는 함수란 뜻 같다) 으로 이 함수 내에서 두 가지를 수행해야 한다.
- cpu의 context를 로컬 스택으로 읽어들인다. 즉 부모의 interrupt frame을 자식의 interrupt frame으로 복사해오는 작업을 여기서 수행한다. 함수의 실행 후 그 결과(return 값)나 system call 번호를 가리키는 rax 레지스터에 0을 넣어주는 코드를 추가한다. 왜냐하면 fork함수의 결과로 child process는 fork를 끝내 0을 반환하기 때문이다. 이 작업은 뒤에 해도 괜찮을 거 같은데, 상단에서 복사하는 김에 아래에 넣어주었다. (그런데 포스트를 작성하며 다시 보니, 맨 아래에 두는 게 맞을 거 같기도 하다. 만약 도중 작업이 잘못된다면 완료된 게 아닌데도 0을 반환하는 게 되지 않을까? 흠.)
- Page Table을 복제한다. 핀토스 내의 함수를 활용하여 pml4 를 복사한다.
- 프로세스에 딸린(?) File을 복제하는데 주석을 참조해서 함수가 성종적으로 부모의 리소스를 복제하기 전까진 fork에서 반환하면 안 된다고 한다. 주어진 file관련 함수들을 사용해서 복제하는데... FDCOUNT_LIMIT처럼 파일 디스크립터의 limit를 미리 설정하고 루프하며 한 땀 한 땀 복사한다. 작업이 끝나면 현재 thread의 fork sema를 up해준다.
- 현재 __do_fork 의 current는, 부모/자식 중 자식 스레드이다. 자식 스레드의 fork_sema는 현재 process_fork 내부에서 thread_create에 __do_fork함수를 전달한 뒤, sema_down하여 wait리스트에 들어가 있다. 내가 이해한 바로는 먼저 생성되어 활동하는 부모 thread A가 자식 thread B의 온전한 fork의 종료가 이루어질 때까지 대기하는 원리로 이해했다.
- 이 상황에서 sema_up을 해주어 thread_unblock하여 대기열에 올린다.
- do_iret(링크)으로 context switcing 한다.
- 에러가 발생할 시에도 sema_up을 해주되, TID_ERROR 를 반환하여 실패함을 알린다.
/* A thread function that copies parent's execution context.
* Hint) parent->tf does not hold the userland context of the process.
* That is, you are required to pass second argument of process_fork to
* this function. */
static void
__do_fork (void *aux) {
struct intr_frame if_;
struct thread *parent = (struct thread *) aux;
struct thread *current = thread_current();
/* TODO: somehow pass the parent_if. (i.e. process_fork()'s if_) */
struct intr_frame *parent_tf = &parent->parent_tf;
bool succ = true;
/* 1. Read the cpu context to local stack. */
memcpy (&if_, parent_tf, sizeof (struct intr_frame));
if_.R.rax = 0;
/* 2. Duplicate PT */
current->pml4 = pml4_create();
if (current->pml4 == NULL)
goto error;
process_activate (current);
#ifdef VM
supplemental_page_table_init (¤t->spt);
if (!supplemental_page_table_copy (¤t->spt, &parent->spt))
goto error;
#else
if (!pml4_for_each (parent->pml4, duplicate_pte, parent))
goto error;
#endif
/* TODO: Your code goes here.
* TODO: Hint) To duplicate the file object, use `file_duplicate`
* TODO: in include/filesys/file.h. Note that parent should not return
* TODO: from the fork() until this function successfully duplicates
* TODO: the resources of parent.*/
if (parent->fd_idx == FDCOUNT_LIMIT) {
goto error;
}
for (int i = 0; i < FDCOUNT_LIMIT; i++) {
struct file *file = parent->fd_table[i];
if (file == NULL) continue;
if (file > 2) {
file = file_duplicate(file);
}
current->fd_table[i] = file;
}
current->fd_idx = parent->fd_idx;
sema_up(¤t->fork_sema);
// process_init ();
/* Finally, switch to the newly created process. */
if (succ)
do_iret (&if_);
error:
sema_up(¤t->fork_sema);
exit(TID_ERROR);
}
노션에서 옮겨서 정리 중..
[Filesys related] :open, close, create, read, write, seek, tell, ...
이 항목으로 묶인 시스템 콜은 '파일시스템'과 관련된 것들이다. 즉, 'process가 다루는 데이터들을 관리할 때 쓰는 system call'들을 filesystem related syscall이라고 할 수 있다.(파일 시스템에 대한 포스트)
create
Creates a new file called file initially initial_size bytes in size
처음에 initial size의 새 파일을 만들고, 성공여부를 반환한다.
새 파일을 create하지만 open하지 않는다. 이는 별도의 시스템 호출이 필요하다.
bool create (const char *file, unsigned initial_size) {
check_address(file);
//validate_buffer(file, initial_size, true);
lock_acquire(&file_lock);
bool res = filesys_create(file, initial_size);
lock_release(&file_lock);
return res;
}
Seek & Tell
Changes the next byte to be read or written in open file fd to position,
expressed in bytes from the beginning of the file
- seek과 tell은 system call의 일부로 파일 입출력에서 주로 사용된다.
- seek: 파일 내에서 특정 위치로 이동하고 싶을 때 사용한다. 파일의 시작/끝/현재위치에서부터의 상대적인 위치를 기준으로 이동하며 정확히 read/write할 위치를 지정하는 데 쓰인다.
- tell: 현재 파일 포인터의 위치를 알아낼 때 사용함. 파일 내에서 현재 위치를 반환하며, read/write 시 시작 지점을 결정할 때 쓰이며, 순차적/혹은 특정 부분으로의 점프 모두 가능하다.
- 열린 파일의 FD에서 읽거나 쓸 다음 bytes를 파일의 시작점에서부터 bytes로 표현된 poisition으로 변경한다.
- 파일의 현재 끝을 지나서 찾는 것은 오류가 아니고, later read(파일의 끝을 읽으면?) 0바이트를 얻는다. later write는 파일을 확장하고, 쓰이지 않은 부분을 0으로 채운다. 그러나 pintOS에서는 프로젝트 4 이전까진 파일 길이가 고정되어 있으므로 파일 끝을 지나서 쓰면 오류가 반환된다.
Returns the position of the next byte to be read or written in open file fd
열린 파일 fd에서 읽거나 쓸 다음 byte의 위치를 시작 부분부터 바이트 단위로 반환한다.
void seek (int fd, unsigned position) {
struct file *f = get_file_from_fd_table(fd);
if (f == NULL) {
return;
}
file_seek(f, position);
}
unsigned tell (int fd) {
struct file *f = get_file_from_fd_table(fd);
if (f == NULL) {
return -1;
}
return file_tell(f);
}
struct file *get_file_from_fd_table (int fd) {
struct thread *t = thread_current();
if (fd < 0 || fd >= 128) {
return NULL;
}
return t->fd_table[fd];
}
open
Opens the file called file.
Returns a nonnegative integer handle called a "file descriptor" (fd), or -1
if the file could not be opened.
- file descriptor(FD)인 음이 아닌 정수를 반환(성공시) 하거나 -1(실패, 즉 파일이 열리지 않았을 떄) 를 반환한다.
- 일부 FD(0,1,2)는 명시적으로 특정 상황일 때에만 system call 인자로 유효하게 사용될 수 있으며, open은 이 FD들을 반환하지 않을 것이다.
- 각 프로세스는 독립적인 FD가 있고, child process에게 상속된다.
- 단일/서로 다른 프로세스들에서든 어떤 파일을 한 번 이상 open한다면 각 open은 새로운 FD를 반환하고, 이 독립적인 FD는 각각 다른 call을 통해 닫히며 file position을 공유하지 않는다.
주소가 유효한지 확인 후, lock을 건 뒤 주어진 filesys_open함수로 파일을 연다. 만약 잘못되었다면 -1을 리턴하고 아닐 때 FDT에 파일을 더한다.
int open (const char *file) {
//printf("[syscall open] start with :%p \n", file);
check_address(file);
//printf("[syscall open] addr check passed\n");
lock_acquire(&file_lock);
struct file *file_info = filesys_open(file);
lock_release(&file_lock);
if (file_info == NULL) {
//printf("[syscall open] crushed, file_info:%d\n", file_info);
return -1;
}
int fd = add_file_to_fd_table(file_info);
if (fd == -1) {
//printf("[syscall open] crushed, fd:%d\n", fd);
file_close(file_info);
}
//printf("[syscall open] end with :%d\n", fd);
return fd;
}
int add_file_to_fd_table (struct file *file) {
struct thread *t = thread_current();
struct file **fdt = t->fd_table;
int fd = t->fd_idx;
while (t->fd_table[fd] != NULL) {
if (fd >= FDCOUNT_LIMIT) {
t->fd_idx = FDCOUNT_LIMIT;
return -1;
}
fd++;
}
t->fd_idx = fd;
fdt[fd] = file;
return fd;
}그런데 여기서, FDT에서 기본적으로 제공되는 STD Input, Output, Error를 thread가 생성할 때 FDT를 만드는 동시에 미리 세팅해주어야 한다.
tid_t
thread_create (const char *name, int priority,
thread_func *function, void *aux) {
struct thread *t;
tid_t tid;
// ....
/* filesys */
t->fd_table = palloc_get_multiple(PAL_ZERO, FDT_PAGES);
if (t->fd_table == NULL) {
return TID_ERROR;
}
t->fd_idx = 2;
t->fd_table[0] = 1;
t->fd_table[1] = 2;
// ....
return tid;
}
Close
Closes file descriptor fd.
프로세스를 종료할 때 열려 있는 모든 fd를 암시적으로 닫는다. file_close함수를 사용한다.
void close (int fd) {
struct thread *t = thread_current();
struct file **fdt = t->fd_table;
if (fd < 0 || fd >= 128) {
return;
}
if (fdt[fd] == NULL) {
return;
}
file_close(fdt[fd]);
fdt[fd] = NULL;
}
Read
Reads size bytes from the file open as fd into buffer
- FD로 열린 파일의 bytes를 읽어 buffer에 넣는다. 파일의 끝은 0으로 끝나므로 그 전까지의 사이즈가 파일 사이즈가 된다.
- 실제 읽은(0 앞까지) 읽은 실제 bytes를 반환하거나, 파일 끝(즉, 0을 만나지 않았는데도) 끝날 경우)이 아닌데도 읽을 수 없을 때 -1을 반환한다.
- FD 0은 input_getc() 을 사용해서 키보드에서 읽어들인다.
- 먼저 버퍼를 검증한다. (이건 VM에서 추가한 코드이다)
- fd가 0일 때, 즉 표준입력일 땐 주어진 함수를 사용하여 byte 수를 읽는다.
- fd가 1일 때, 즉 표준출력일 땐 -1을 반환한다.
- 그 외 음이 아닌 정수일 때에는 FDT에서 FD를 가져오고 오류를 검증한다.
- 실제 파일 bytes를 읽는 건 pintOS에서 제공하는 file_read를 활용한다. 이 때 lock을 걸어주어야 한다.(처음에 걸지 않고 코드를 작성하니 오류가 터졌다.)
int read (int fd, void *buffer, unsigned length) {
//printf("[syscall read] start with :%d, %p \n", fd, buffer);
//check_address(buffer);
validate_buffer(buffer, length, true);
int bytesRead = 0;
if (fd == 0) {
for (int i = 0; i < length; i++) {
char c = input_getc();
((char *)buffer)[i] = c;
bytesRead++;
if (c == '\n') break;
}
} else if (fd == 1) {
return -1;
} else {
//printf("[syscall read] fd else start\n");
struct file *f = get_file_from_fd_table(fd);
//printf("[syscall read] f : %p\n", f);
if (f == NULL) {
//printf("[syscall read] f is NULL!\n");
return -1;
}
//printf("[syscall read] fd bf lock\n");
lock_acquire(&file_lock);
bytesRead = file_read(f, buffer, length);
lock_release(&file_lock);
//printf("[syscall read] fd else end\n");
}
return bytesRead;
}
struct file *get_file_from_fd_table (int fd) {
struct thread *t = thread_current();
if (fd < 0 || fd >= 128) {
return NULL;
}
return t->fd_table[fd];
}
Write
Writes size bytes from buffer to the open file fd
- 버퍼에서 가져온 bytes만큼의 크기를 열린 파일 FD에 쓰며, 실제 얼마나 썼는지 수를 반환한다. (만약 일부 바이트를 쓸 수 없다면 그보다 적은 수를 반환한다.)
- 보통 파일 끝을 지나서 쓴다면 파일이 확장되지만 기본적인 시스템으로는 구현하지 않는다. 따라서 파일 끝 부분까지 최대한 쓸 수 있는 만큼 많은 bytes를 쓰고 그 값을 반환하거나, 쓸 수 없는 경우 0을 반환해야 한다.
- console에 쓰는 경우에는 putbuf() 호출 한 번으로 모든 버퍼를 써야 한다(크면 분할하는 게 합리적이다). 그렇지 않다면 서로 다른 프로세스들끼리 출력하는 텍스트 줄이 콘솔에서 서로 섞여서 채점에 오류가 발생할 수 있다.
- 0일 떄는 표준입력이므로 -1 반환
- 1일 때는 표준출력이므로 console에 쓰는 경우. putbuf를 호출한다.
int write (int fd, const void *buffer, unsigned length) {
//check_address(buffer);
//printf("[syscall write] fd:%d\n", fd);
validate_buffer(buffer, length, false);
int bytesRead = 0;
//printf("[syscall write] validate_buffer end\n");
if (fd == 0) {
//printf("[syscall write] fd = %d\n", fd);
return -1;
} else if (fd == 1) {
putbuf(buffer, length);
//printf("[syscall write] bytesRead:%d\n", length);
return length;
} else {
struct file *f = get_file_from_fd_table(fd);
if (f == NULL) {
//printf("[syscall write] f = %p\n", f);
return -1;
}
lock_acquire(&file_lock);
bytesRead = file_write(f, buffer, length);
lock_release(&file_lock);
//printf("[syscall write] lock finished\n");
}
return bytesRead;
}Remove
Deletes the file called file
파일을 삭제하고, 성공시 true를 실패시 false를 반환한다.
파일이 열려 있는지 여부와 상관없이 제거할 수 있고, 열려 있는 파일을 제거해도 닫히지 않는다.
What happens when an open file is removed?
열려 있는 파일을 제거한다면 해당 파일에 대한 FD를 갖는 모든 프로세스가 해당 FD를 계속 사용할 수 있다.(표준 유닉스 시맨틱) 즉, 파일을 읽고 쓸 수 있다. 그 파일은 이름을 갖고 있지 않게 되고, 다른 프로세스가 그 파일을 열 수 없겠지만 해당 파일을 참조하는 모든 FD가 닫히거나 machine이 종료될 때까지 존재한다.
bool remove (const char *file) {
check_address(file);
return filesys_remove(file);
}
System Call Handler
interrupt frame에서 범용레지스터(R) 내부의 rax에 담겨있는 system call number에 따라 분기한다.
인자는 interrupt frame 내부의 레지스터들을 정해진 규칙에 따라 가져와 순서대로 넣는다.
system call이 반환하는 값들은 rax에 다시 넣어준다.
1st arg: %rdi | 2nd arg: %rsi | 3rd arg: %rdx
/* The main system call interface */
void
syscall_handler (struct intr_frame *f) {
//printf("[syscall number] %d\n", f->R.rax);
#ifdef VM
/* When switched into kernel mode,
save stack pointer in thread'*/
thread_current()->intr_rsp = f->rsp;
//printf("[syscall checking] curr intr_rsp %p,\n",thread_current()->intr_rsp);
#endif
switch (f->R.rax) {
case SYS_HALT:
halt();
break;
case SYS_EXIT:
exit(f->R.rdi);
break;
case SYS_FORK:
f->R.rax = fork(f->R.rdi, f);
break;
case SYS_EXEC:
if (exec(f->R.rdi) < 0) {
exit(-1);
}
break;
case SYS_WAIT:
f->R.rax = wait(f->R.rdi);
break;
case SYS_CREATE:
f->R.rax = create(f->R.rdi, f->R.rsi);
//printf("[syscall] created file:%p \n", f->R.rax);
break;
case SYS_REMOVE:
f->R.rax = remove(f->R.rdi);
break;
case SYS_OPEN:
f->R.rax = open(f->R.rdi);
//printf("[syscall switch] fd?:%d\n", f->R.rax);
break;
case SYS_FILESIZE:
f->R.rax = filesize(f->R.rdi);
break;
case SYS_READ:
f->R.rax = read(f->R.rdi, f->R.rsi, f->R.rdx);
break;
case SYS_WRITE:
f->R.rax = write(f->R.rdi, f->R.rsi, f->R.rdx);
break;
case SYS_SEEK:
seek(f->R.rdi, f->R.rsi);
break;
case SYS_TELL:
f->R.rax = tell(f->R.rdi);
break;
case SYS_CLOSE:
close(f->R.rdi);
break;
default:
exit(-1);
}
//printf("[syscall] end \n");
}Deny Write on Executables
디스크에서 불러와 변경(사용)중인 코드를 실행하려고 할 때 예측할 수 없는 결과가 발생하는 것을 방지하기 위해 실행 파일로 사용 중인 파일에 대한 쓰기를 거부한다. file_deny_write를 사용할 수 있고, file_allow_write를 호출하면 다시 활성화된다. 프로세스의 실행 파일 쓰기 거부를 위해선 프로세스가 실행되는 동안 파일을 계속 열어 두어야 한다.
process.c 내부의 load에서, '실행 파일로 사용 중인 파일에 대한 쓰기'를 거부한다.
static bool
load (const char *file_name, struct intr_frame *if_) {
struct thread *t = thread_current ();
struct ELF ehdr;
struct file *file = NULL;
off_t file_ofs;
bool success = false;
int i;
/* Allocate and activate page directory. */
// ...
/* Open executable file. */
lock_acquire(&file_lock);
file = filesys_open (file_name);
lock_release(&file_lock);
if (file == NULL) {
printf ("load: %s: open failed\n", file_name);
goto done;
}
t->running = file;
file_deny_write(file);
/* Read and verify executable header. */
// ...
/* Read program headers. */
// ....
}
Troubles
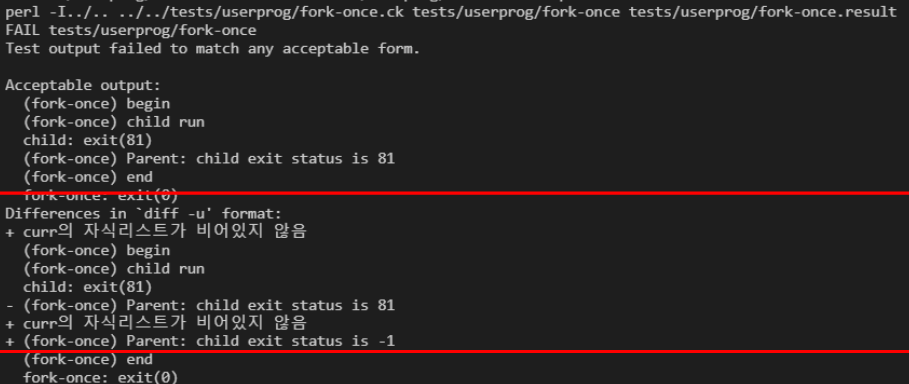
fork 중 마주친 오류였는데, 반환 값을 rax에 제대로 넣어주지 않아서 생긴 오류였다.


페이지를 할당할 때 0으로 청소하지 않으면 쓰레기 값이 들어가 오류가 터졌다. 페이지를 할당할 땐 깨끗히 청소하고 주어야 함을 몸으로 배웠다.

syn-read 에서 성공하다가, 성공하지 않을 때도 있었다. 도대체 왜 이럴까?
마무리하며
Extend File Descriptor (Extra) 는 구현하지 못해서 아쉬웠다. 나중에 이론이라도 한번 다시 봐야겠다.
project 2 기간엔 강의실에 코로나가 유행해서 다들 고생했던 주였다.

'공부기록 > OS' 카테고리의 다른 글
| [TIL] [Project 2 보충] Filesystem, Buffer, syn-read issue (0) | 2023.12.19 |
|---|---|
| [TIL][Setting] ubuntu Setting for PintOS (0) | 2023.12.18 |
| [WIL / PintOS] [Project 2] Argument Passing | User Memory (0) | 2023.12.15 |
| [WIL / PintOS] [Project 2] User Program | Keywords (0) | 2023.12.14 |
| [TIL / WIL] [Project 1] MLFQS + Advanced Scheduler in PintOS (0) | 2023.12.04 |